Following my previous
post, I am again looking at how to employ R and Python seamlessly to
use large language models (LLMs). Last time, I scraped information off
of Wikipedia using the rvest package, fed that information
to OpenAI’s Python API, and asked it to extract information for me.
But what if we could skip that scraping step? What if we had a more
complex question where writing an rvest or
RSelenium script was not feasible?
Enter the LangChain
Python library. I recently read Generative
AI with LangChain and Developing
Apps with GPT-4 and ChatGPT, both of which do a fabulous job of
introducing LangChain’s capabilities.
I’ve been thinking of LangChain as an LLM version of scikit-learn: It
is a model-agnostic framework where you can build LLM pipelines. Most
relevant to our needs here, though, is that you can employ tools
in these pipelines. Tools allow the LLM to rely on integrations to
answer prompts. One tool is Wikipedia, which allows the LLM to search
and read Wikipedia in trying to answer the question it’s been given.
This is especially useful if you want to ask it information about
something that happened after it was trained.
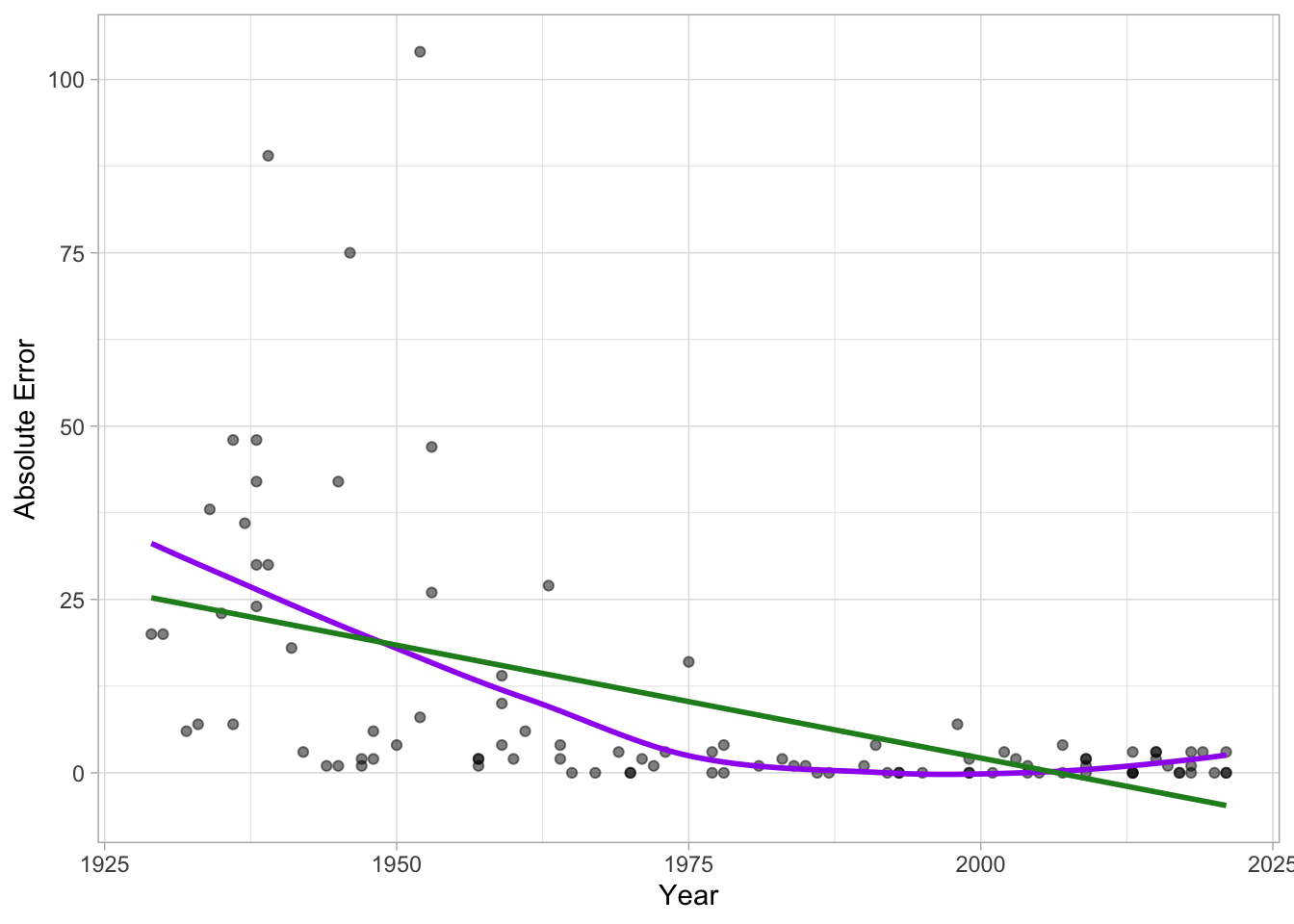
I’m continuing to use my Best Picture model as
the project, using LLMs to get more features for me to add to it. This
means I’m mostly using LLMs as information extractors instead
of information generators. Does this really map one-to-one with
what something like GPT 3.5 Turbo was meant to do? I truly don’t know. I
don’t think many people know what the hell these things can and should
be used for. Which is why I’m testing it and reporting out the accuracy
here!
Question
Past Lives (my favorite
movie of last year) was nominated for Best Picture, even though it
was director Celine Song’s debut feature-length film. This is rare, and
I think a helpful feature for my Best Picture model would be how many
films the director had directed before the nominated film.
Getting this information is a bit more complicated. It would involve
an RSelenium script of going to the movie’s page, finding
the director, clicking on their profile, and then either pulling down
filmography information from there or by clicking into their filmography
page. Pages aren’t formatted the same, either. Sometimes the section is
“Filmography,” sometimes it is “Works,” sometimes the information is in
a table, while other times it is in a bulleted list.
The idea here is to use LangChain to give an LLM the
Wikipedia tool to find this information for me. As opposed to my last
post, I am not giving it the relevant slice of info from Wikipedia
anymore. Instead, I asking it a question and giving it Wikipedia as a
tool to use itself.
Methodology
I took the following steps:
Wrote a prompt that asks an LLM to figure out how many
feature-length films the director of a movie had directed
before making a film. The prompt is a template that takes a
film’s name and release year.
Give the LLM the Wikipedia tool and a calculator (my thinking was
it might need this to sum up the number of movies, since these models
are optimized on language, not math).
Collect and clean the responses for every movie that’s been
nominated for Best Picture.
Test the accuracy by hand-checking 100 of these cases.
The Prompt and Function
I started by making a file named funs.py:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.agents import load_tools, AgentExecutor, create_openai_tools_agent
from re import sub
model = ChatOpenAI(
model="gpt-3.5-turbo",
temperature=0,
openai_api_key="API_KEY_GOES_HERE"
)
tools = load_tools(["wikipedia", "llm-math"], llm=model)
prompt = ChatPromptTemplate.from_messages(
[
("system", """You are a helpful research assistant, and your job is to
retrieve information about movies and movie directors. Think
through the questions you are asked step-by-step."""),
("human", """How many feature films did the director of the {year} movie
{name} direct before they made {name}? First, find who
directed {name}. Then, look at their filmography. Find all the
feature-length movies they directed before {name}. Only
consider movies that were released. Lastly, count up how many
movies this is. Think step-by-step and write them down. When
you have an answer, say, 'The number is: ' and give the
answer."""),
MessagesPlaceholder("agent_scratchpad")
]
)
agent = create_openai_tools_agent(model, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, max_iterations=6)
def prior_films(year, film):
resp = agent_executor.invoke({"year": year, "name": film})
return(resp['output'])
It turns out that many of the functions in the two books above,
despite being Published in October and December of 2023, have been
deprecated (but the author of Developing Apps has published updated code and
a second version of the book is being released this year). This is a
good reminder of how quickly this field is moving, and it’s OK to not be
entirely sure how to use these models—so long as you have appropriate
respect for that lack of knowledge. This is to say: I’m no expert here.
What I have above is cobbled together from LangChain docs, StackOverflow
posts, and GitHub threads. The prompt here lays out the basic steps it
should be following to get the information.
Bringing It To R
I wrote an R script to use this function in an R session. Why?
Because I think the tidyverse makes it easier to inspect,
clean, and wrangle data than anything in Python currently.
We start off by loading the R packages, sourcing the R script,
activating the Python virtual environment (the path is relative to my
file structure in my drive), and sourcing the Python script. I read in
the data from a Google Sheet of mine and do one step of cleaning, as the
read_sheet() function was bringing the title variable in as
a list of lists instead of a character vector. I then initialize a new
column, resp, where I will collect the responses from the
LLM.
library(googlesheets4)
library(tidyverse)
library(reticulate)
use_virtualenv("../../")
source_python("funs.py")
dat <- read_sheet("SHEET_ID_GOES_HERE") %>%
mutate(film = as.character(film)) %>%
select(year, film) %>%
mutate(resp = NA)
I iterate through each film using a for loop. This is
not the R way, I know, but if something snags, I want to catch the
response that I’m paying for. You’ll see that I take extra precautions
to catch everything by writing out the results in .csv row-by-row. (My
solution because I had been running this script and got an aborted R
session in the middle and lost everything.)
for (r in 1:nrow(dat)) {
cat("prompting", r, "\n")
dat$resp[r] <- str_replace_all(
prior_films(dat$year[r], dat$film[r]),
fixed("\n"),
" "
)
cat("writing", r, "\n")
if (r == 1) {
write_csv(dat[r, ], "prior_films.csv")
} else {
write_csv(dat[r, ], "prior_films.csv", append = TRUE)
}
Sys.sleep(runif(1, 2, 10))
}
As I said in my previous post, this is an example of how we can use R
and Python together in harmony. prior_films is a Python
function, but we use it inside of an R script.
An example call that returns the correct information:
> prior_films(2017, "phantom thread")
[1] "The director of the movie \"Phantom Thread\" is Paul Thomas Anderson. Before directing \"Phantom Thread\" in 2017, Paul Thomas Anderson directed the following feature-length movies that were released:\n\n1. Hard Eight (1996)\n2. Boogie Nights (1997)\n3. Magnolia (1999)\n4. Punch-Drunk Love (2002)\n5. There Will Be Blood (2007)\n6. The Master (2012)\n7. Inherent Vice (2014)\n\nThe number of feature films that Paul Thomas Anderson directed before making \"Phantom Thread\" in 2017 is 7."
I then pulled in this .csv to a separate cleaning script. Since I
asked it for standardized feedback, I could use a regular expression to
clean most of the responses. I read the rest myself. This went into a
new column called resp_clean, with only the integer
representing the number of movies the director had directed before the
movie in question.
library(tidyverse)
dat <- read_csv("prior_films.csv")
dat <- dat %>%
mutate(
resp_clean = case_when(
str_detect(tolower(resp), "the number(.*)is") ~
str_split_i(tolower(resp), "the number(.*)is", 2)
),
resp_clean = str_remove_all(resp_clean, "[^0-9]")
)
# manual code the rest
lgl <- !is.na(dat$resp) &
dat$resp != "Agent stopped due to max iterations." &
is.na(dat$resp_clean)
dat$resp[lgl] # read with mine own human eyes
dat$resp_clean[lgl] <- c(NA, NA, 44, NA, NA,
NA, NA, NA, NA, NA,
4, NA, NA, 86, NA,
9, NA, 4, 33, 26)